 kms
kms
Benchmarking Large Riak Data Types
Riak 2.0 includes Data Types which provide reasonable guarantees with regard to eventual consistency. However, the data types, as implemented, aren’t really designed to be performant with a large number of elements.
To that end, here’s a benchmark which demonstrates the behavior of large maps and sets using the Riak Ruby Client. First, it reads using the key-value API and gets the size of the object (number of bytes, not number of elements). Then, using the data-type API, it reads, adds an element, and reads twice. This allows us to compare read performance between the APIs, as well as examine performance relative to the number of elements or bytes.
require 'riak'
require 'benchmark'
require 'securerandom'
data_type = "maps" # or "sets"
bucket = "testing CRDT #{data_type}: #{SecureRandom.hex}"
n_items = 15000
n_containers = 1
client = Riak::Client.new(nodes: [{:host => 'localhost', :pb_port => 8087}])
puts 'items, id, size, kv_read_elapsed, read_prewrite_elapsed, write_elapsed, read_postwrite_elapsed, read_postwrite_elapsed2'
(1..n_items).each do |i|
(1..n_containers).each do |id|
key = id.to_s
size = 0
kv_read_elapsed = 0
begin
kv_read_elapsed = Benchmark.realtime do
size = client.bucket(bucket).get(key, type: data_type).content.raw_data.size
end
rescue Riak::ProtobuffsFailedRequest
# get will fail the first time through.
end
container = nil
read = nil
write = nil
if data_type == "maps"
read = lambda{ container = Riak::Crdt::Map.new(client.bucket(bucket), key) }
write = lambda{ container.sets['set'].add(i.to_s) }
elsif data_type == "sets"
read = lambda{ container = Riak::Crdt::Set.new(client.bucket(bucket), key) }
write = lambda{ container.add(i.to_s) }
end
read_prewrite_elapsed = Benchmark.realtime &read
write_elapsed = Benchmark.realtime &write
read_postwrite_elapsed = Benchmark.realtime &read
read_postwrite_elapsed2 = Benchmark.realtime &read
puts "#{i}, #{id}, #{size}, #{kv_read_elapsed}, #{read_prewrite_elapsed}, #{write_elapsed}, #{read_postwrite_elapsed}, #{read_postwrite_elapsed2}"
end
endResults
I ran the benchmark for 5,000 items in a Map, and 10,000 items in a Set against a single local node.
For both Sets and Maps, size has near-linear growth relative to the number of items1.
Set reads for both the key-value and data-type APIs are small and seemingly constant.2 These are nearly flat lines, so I didn’t include the plots. The same goes for Map reads using the key-value API, but not Map reads using the data-type API:
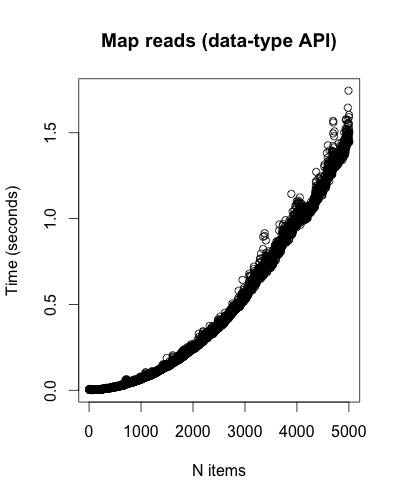
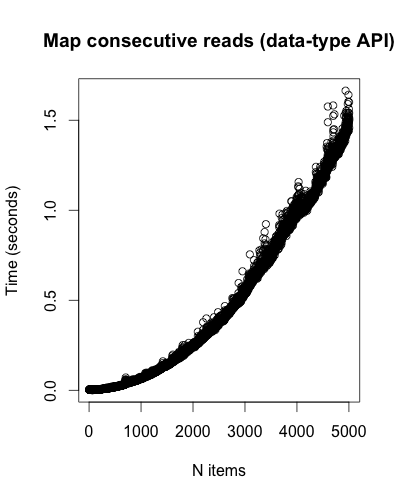
Consecutive reads don’t seem to have much of an effect:
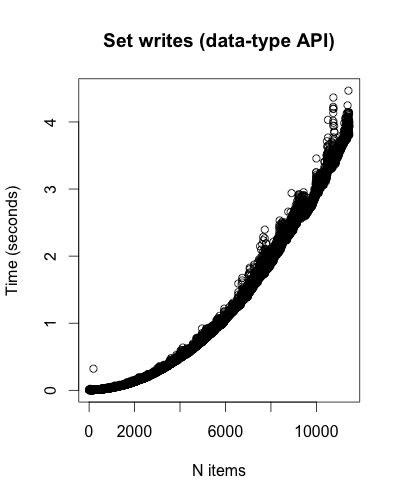
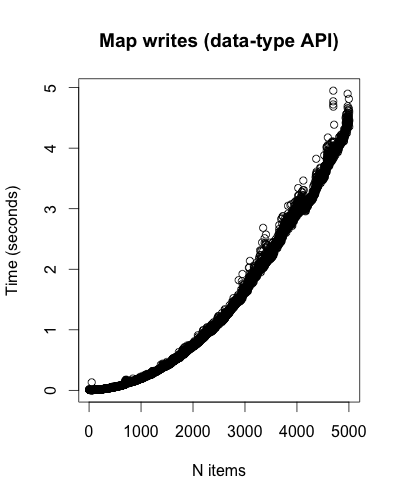
Both Set and Map writes seem to grow superlinear:
Future work
I haven’t tested this against a Riak cluster rather than a single local node, though similar behavior has been seen in both. basho_bench could be used to test without using the Ruby client. Additionally, I’d like to test the data types directly.
Update: For some missing graphs, and more information about my environment, please see my next post.
Update #2: Russell Brown may have fixed this in a feature branch. I ran the benchmark against the potential fix with good results.